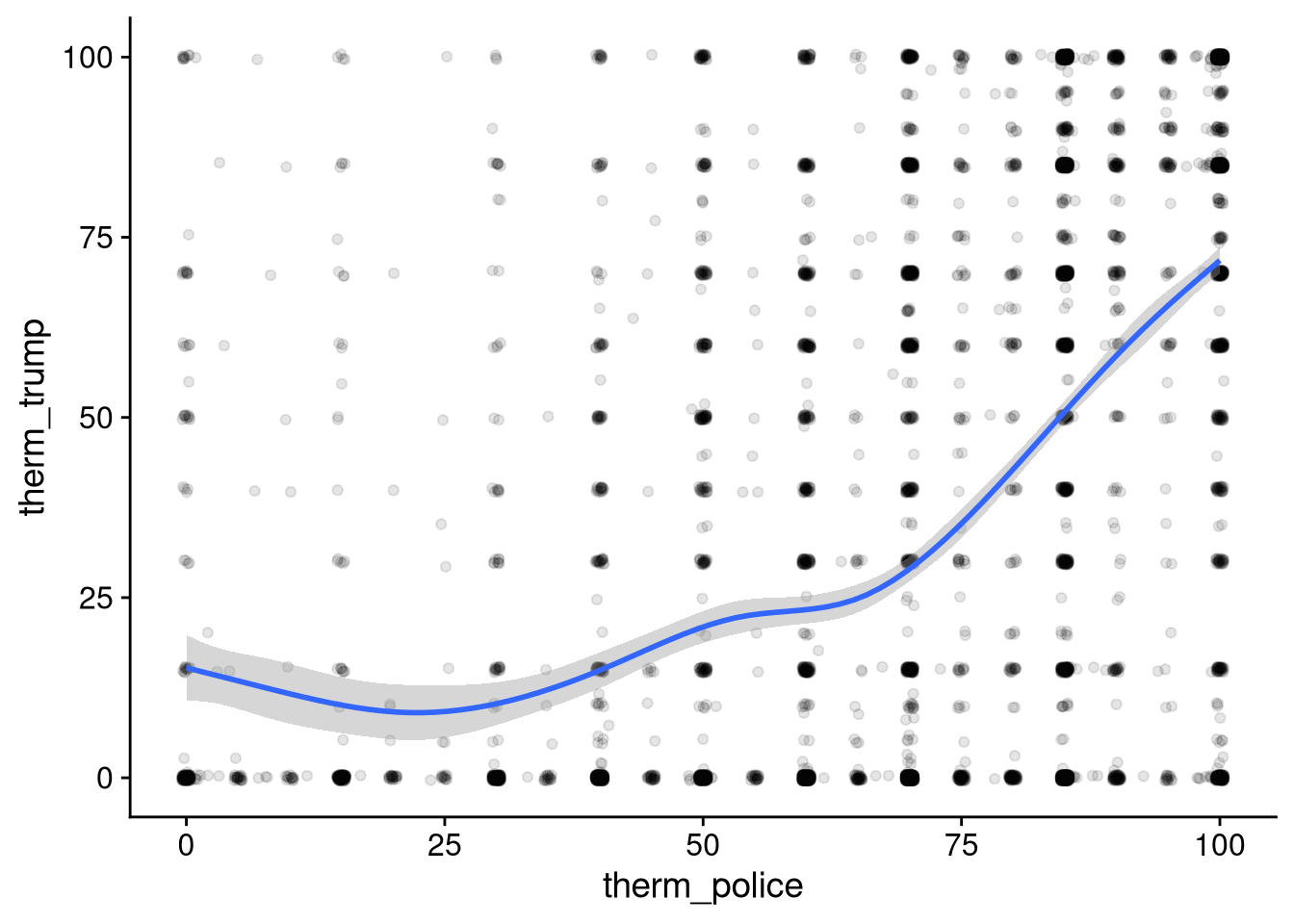
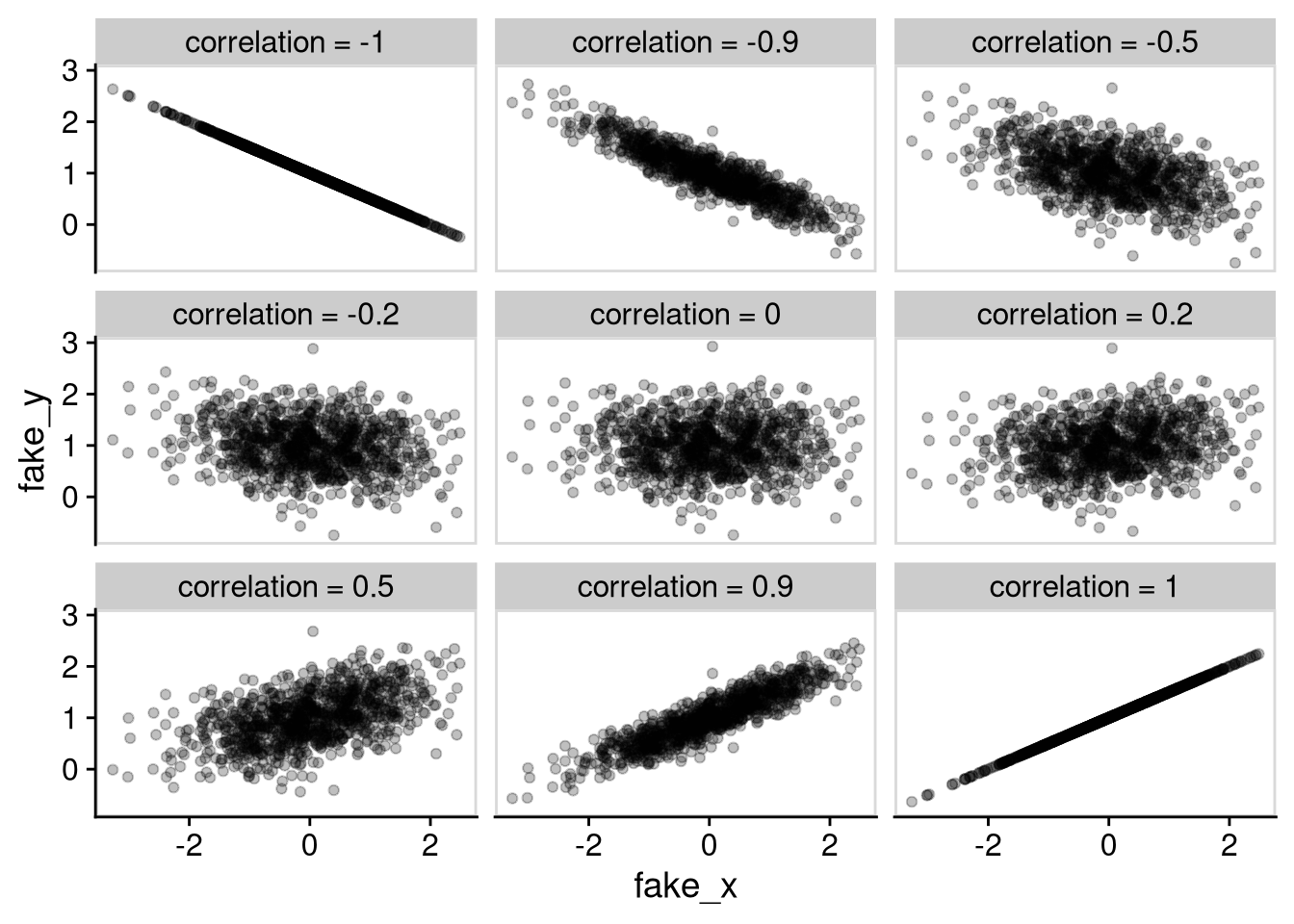
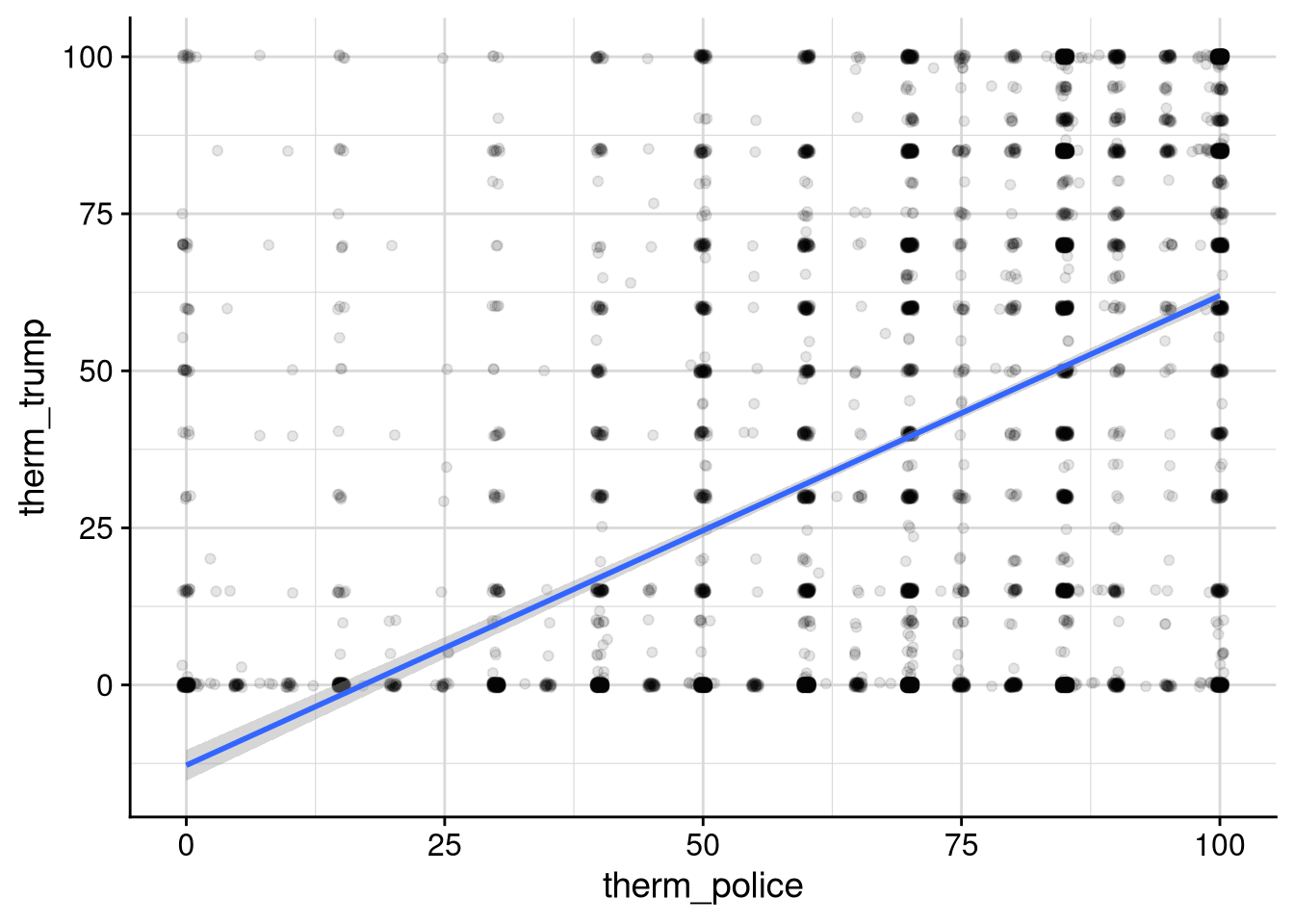
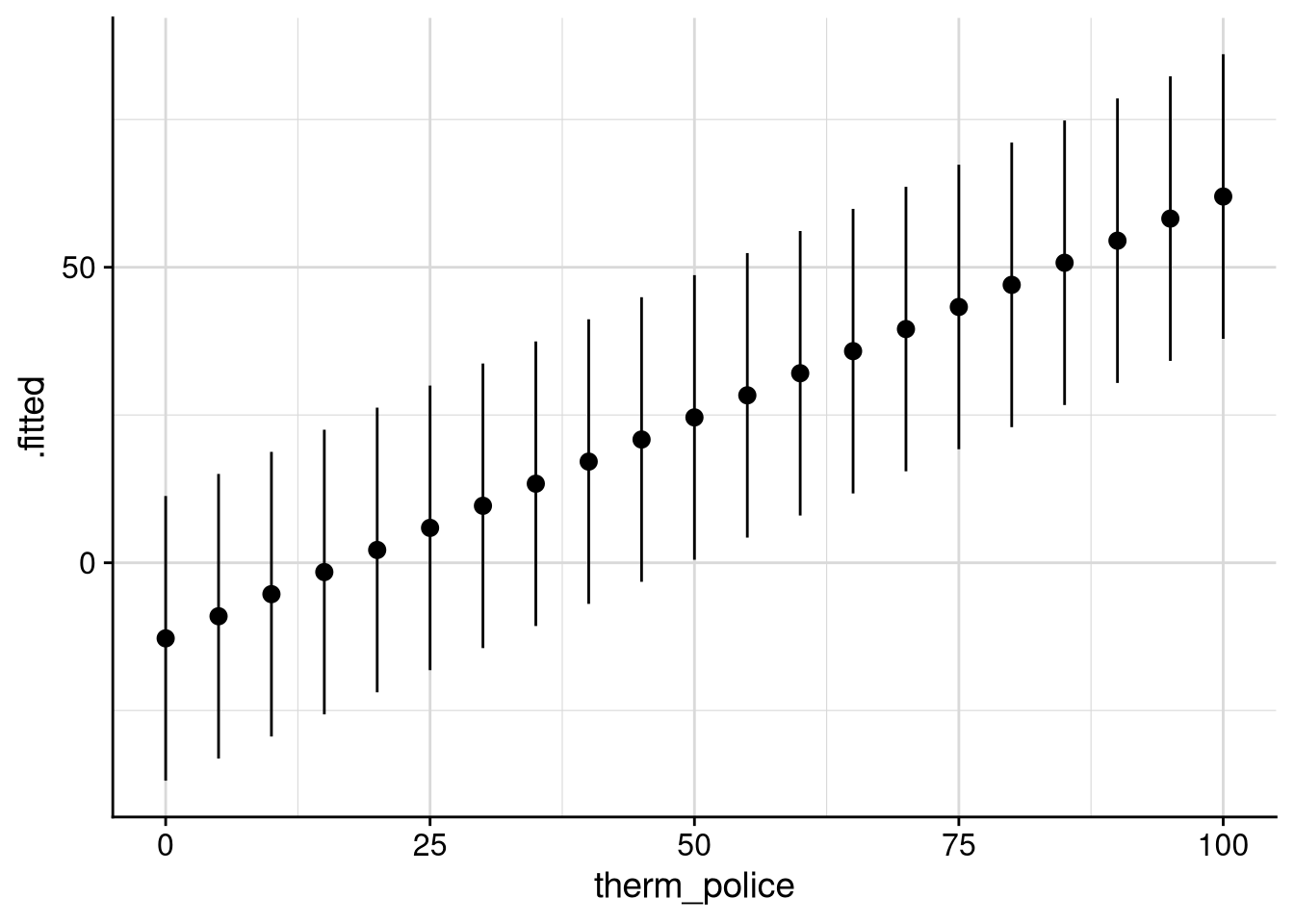
Rows: 8,280
Columns: 31
$ id <dbl> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13…
$ state <chr> "Oklahoma", "Idaho", "Virginia", "Califor…
$ female <dbl> 0, 1, 1, 0, 0, 1, 1, 1, 1, 0, 1, 0, 1, 0,…
$ lgbt <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,…
$ race <chr> "Hispanic", "Asian", "White", "Asian", "N…
$ age <dbl> 46, 37, 40, 41, 72, 71, 37, 45, 70, 43, 3…
$ education <chr> "Bachelor's degree", "Some college", "Hig…
$ employed <dbl> 1, 1, 0, 1, 0, 0, 1, 0, 0, 1, 1, 1, 0, 0,…
$ hours_worked <dbl> 40, 40, 0, 40, 0, 0, 30, 40, 0, 30, 25, 5…
$ watch_tucker <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,…
$ watch_maddow <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,…
$ therm_biden <dbl> 0, 0, 65, 70, 15, 85, 50, 50, 85, 85, 100…
$ therm_trump <dbl> 100, 0, 0, 15, 85, 0, 75, 100, 0, 0, 0, 0…
$ therm_harris <dbl> 0, 0, 65, 85, 15, 85, 15, 50, 85, 50, 100…
$ therm_pence <dbl> 85, 0, 0, 15, 90, 0, 75, 50, 0, 50, 0, 50…
$ therm_obama <dbl> 0, 50, 90, 85, 10, 60, 15, 50, 60, 100, 1…
$ therm_dem_party <dbl> 0, 0, 60, 50, 20, 85, 15, 50, NA, 60, 100…
$ therm_rep_party <dbl> 85, 50, 0, 70, 70, 15, 75, 100, NA, 50, 0…
$ therm_feminists <dbl> 65, 100, 75, 70, 30, 60, 60, 100, 50, 50,…
$ therm_liberals <dbl> 30, 0, 75, 70, 10, 70, 0, NA, 30, 50, 50,…
$ therm_labor_unions <dbl> 30, 70, 75, 70, 50, 50, 50, 0, 30, 50, 50…
$ therm_big_business <dbl> 70, 50, 0, 85, 0, 40, 50, 0, 50, 15, 50, …
$ therm_conservatives <dbl> 85, 15, 0, 70, 60, 40, 60, NA, 50, 50, 50…
$ therm_supreme_court <dbl> 100, 50, 25, 85, 60, 60, 70, 50, 50, 50, …
$ therm_congress <dbl> 40, 15, 0, 100, 10, 85, 50, 50, 50, 40, 5…
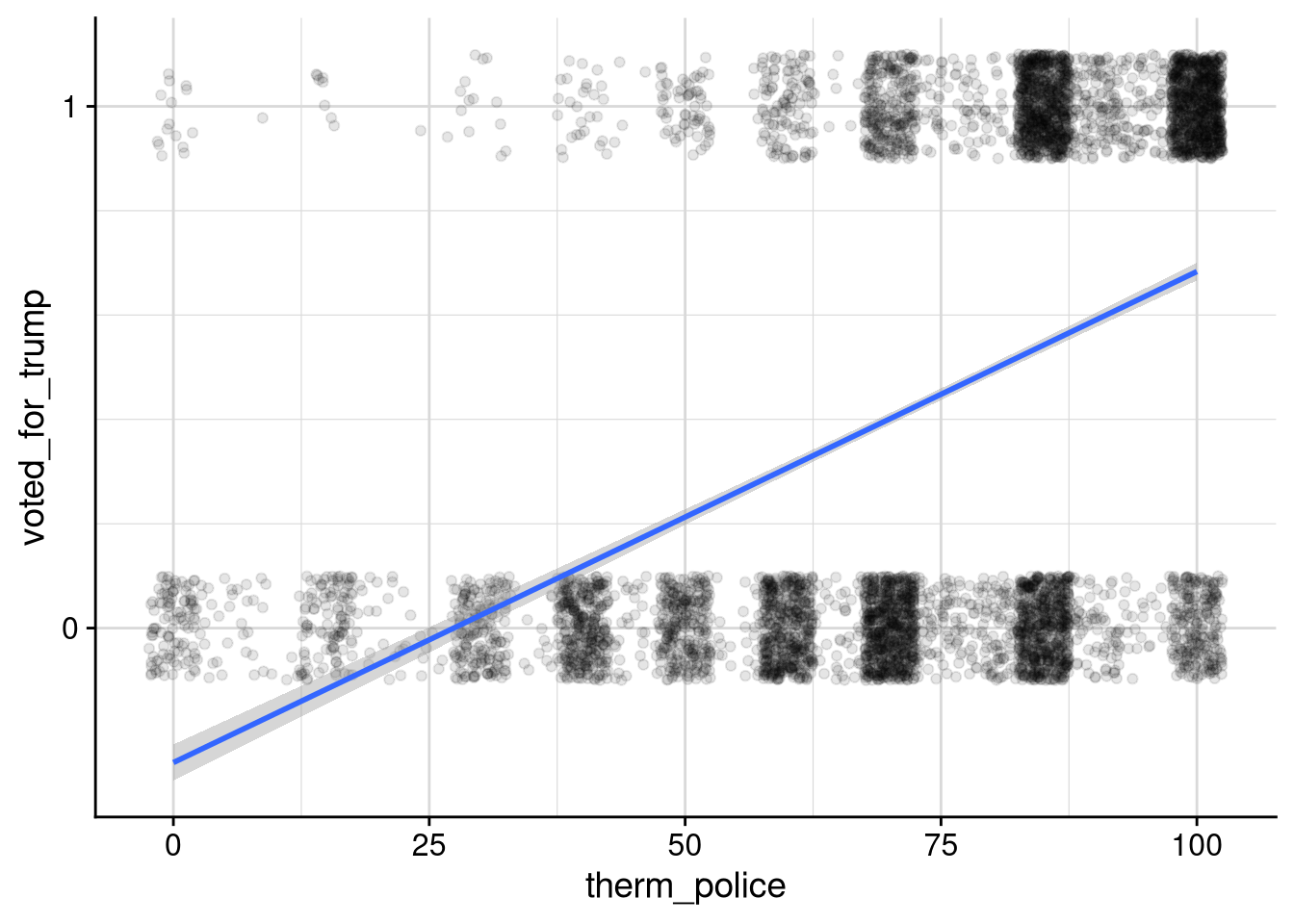
$ therm_police <dbl> 85, 90, 40, 100, 70, 70, 60, 100, 60, 70,…
$ therm_scientists <dbl> 100, 70, 100, 85, 60, 85, 85, NA, 60, 50,…
$ contributed_to_party <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,…
$ voted <dbl> 0, 1, 1, 1, 1, 1, 1, 0, 1, 1, 1, 1, 1, 1,…
$ voted_for_biden <dbl> NA, 0, 1, 1, 0, 1, 0, NA, NA, 1, 1, 1, 0,…
$ voted_for_trump <dbl> NA, 0, 0, 0, 1, 0, 1, NA, NA, 0, 0, 0, 1,…